Validation
Tested in practice
0%
Cost Reduction
$0
Per 1M responses
$0
Original cost
0.0%
Quality preserved
Internal Case Study: Mental Health Conversational AI
Main challenge: Keep quality estimated and data-driven
Results
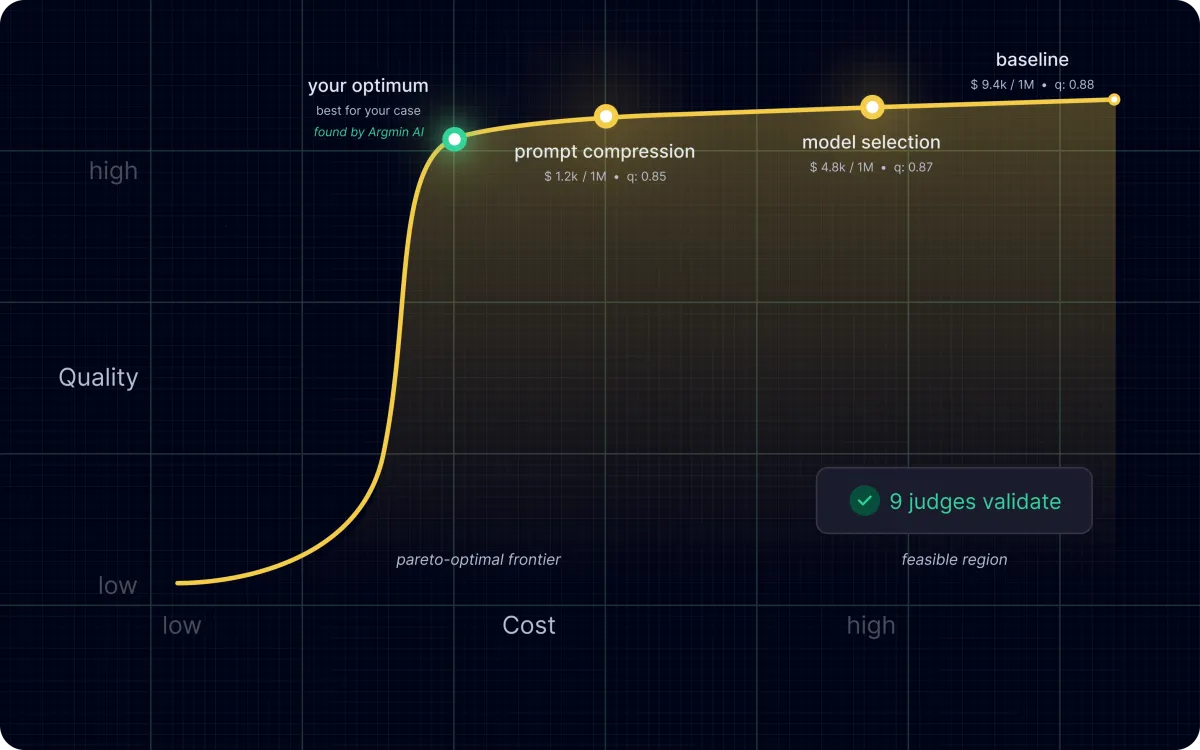
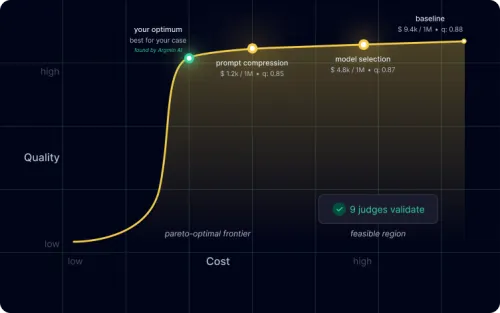
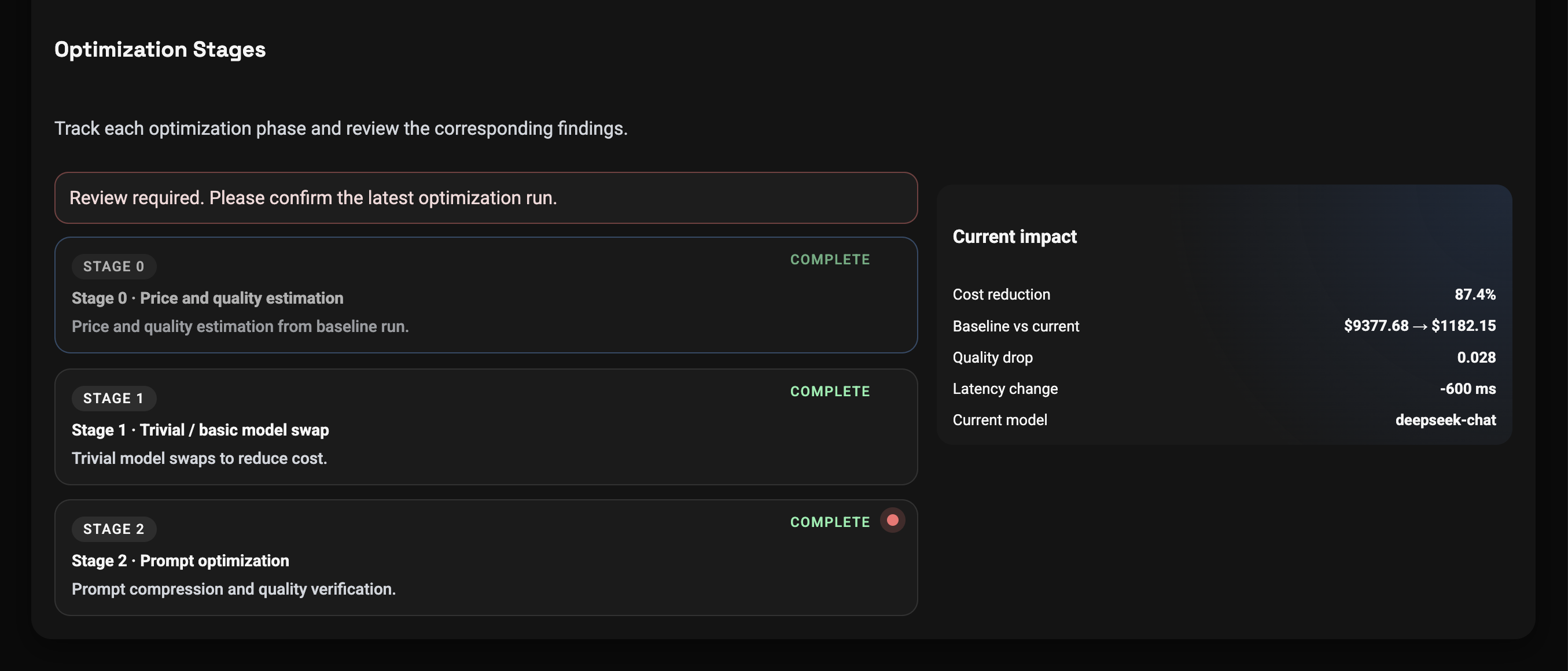
- Cost reduction — 87%
- Quality preserved — only 3.3% degradation
- Clinical safety maintained — 97.6%
- 9-judge LLM-as-a-Judge validation
- 400-item edge-case stress test
Learn a reusable decision framework, metrics, and rollout steps from our Data-Driven LLM Optimization Case Study
To help prevent overuse of the document, we kindly ask you to submit your email — we will send you a one-time download link.
We process your email to provide access and start the whitepaper delivery flow. You can read our Privacy Policy.
Research Foundation
The platform helps you find techniques that fit your case perfectly.*
*Selected public research references we build on, with credit to the original authors. Not Argmin AI research and not a complete list.
Process
How it works
A quick guide to using the platform for optimization.
Estimate Potential Savings
Before you start optimizing, use the cost potential calculator to check whether optimization makes sense for your use case and how much you could save.
Estimate savings
Prepare for Quality Evaluation
Connect your agent and data. If you need test data, we can help generate it.
We respect your intellectual property and can sign an NDA at this stage.
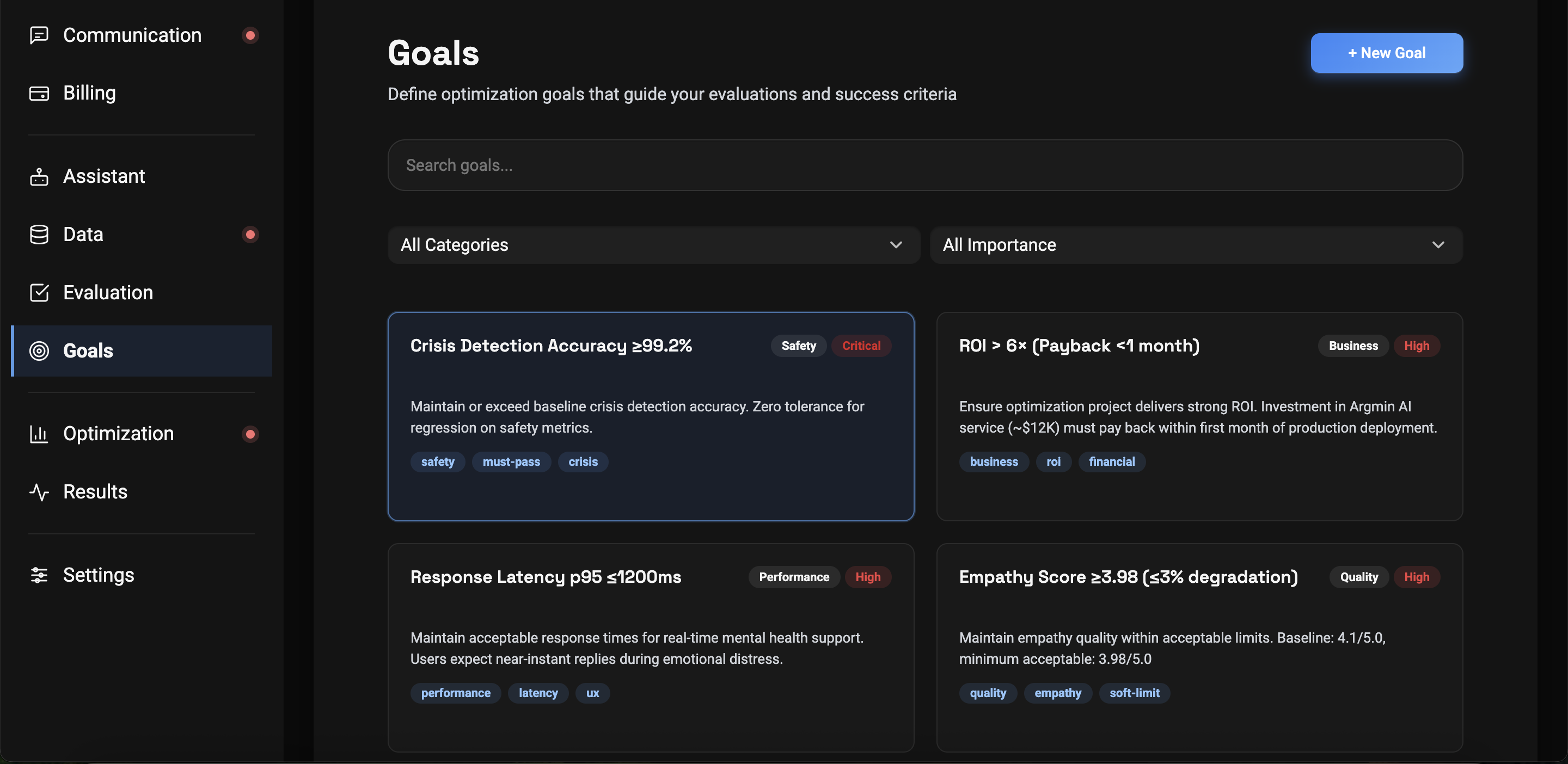
Define Your Goals and Priorities
Share what you expect from optimization and what is most important to you.
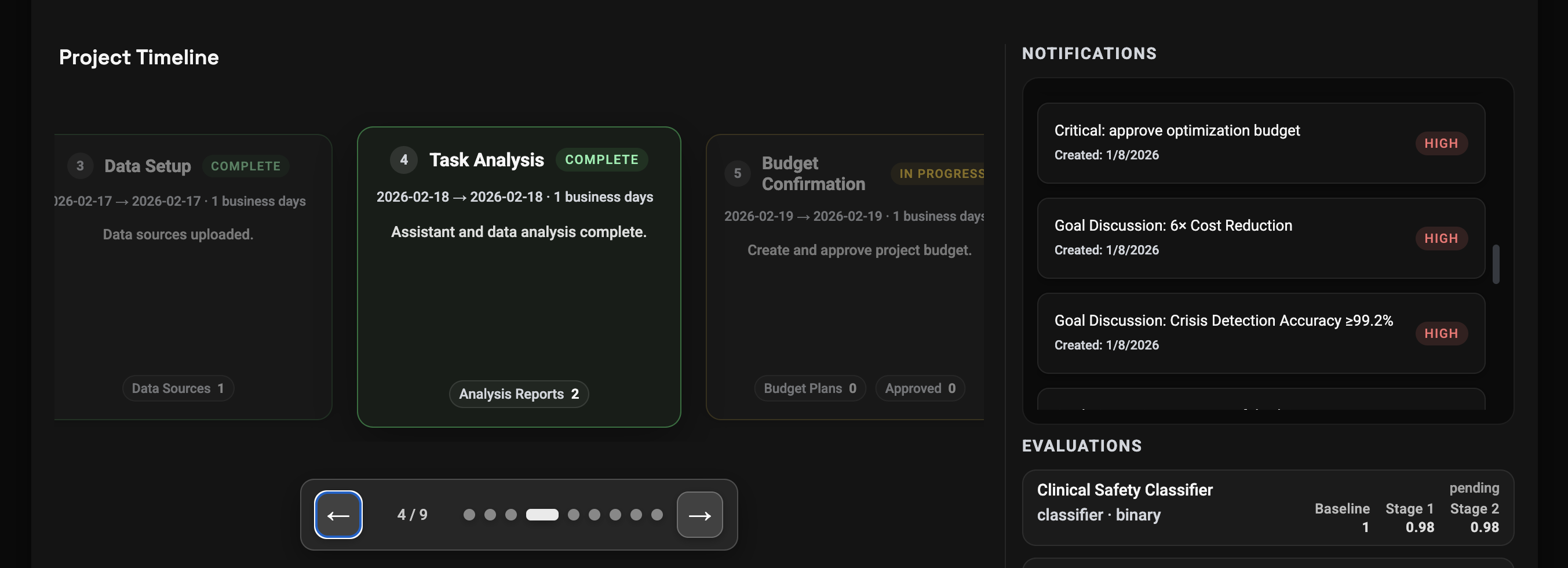
See Your Budget and Next Steps
Before optimization starts, the platform will define the budget and plan the next steps.
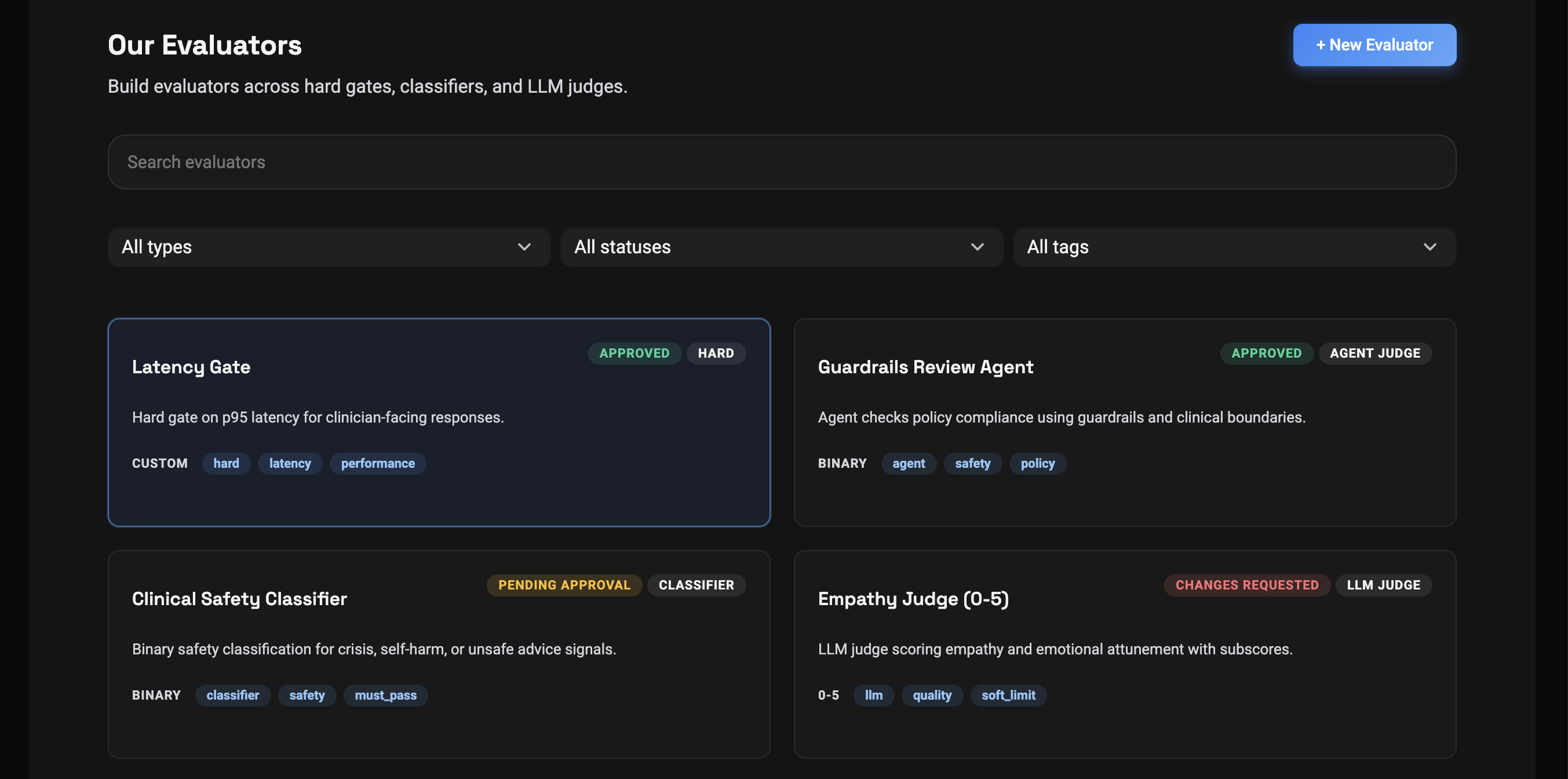
Establish Quality Evaluators
The platform generates a full set of quality evaluators for you. You review them and stay in control.
Get an Optimized Agent
Argmin AI improves LLM efficiency and production reliability across the full inference pipeline. It gives you several options tailored to your use case.
Judge Builder
Build evaluators you can trust
Watch a short walkthrough of how Judge Builder turns your data into calibrated, production-ready quality evaluators.
Where Argmin AI delivers value*
Use cases
Key benefits & features

Spend Less at Scale
10x inference cost reduction for many real-world tasks

Plug In Quickly
Fast integration into existing LLM and agent pipelines

Works Across Providers
Model-agnostic: works with proprietary and open-source LLMs

Security & Risk-Free Start
NDA coverage, a phased engagement, and a free initial analysis to validate bottlenecks and savings potential
No retraining / No vendor lock-in / No risky rewrites